Probability¶
Random Variables¶
Suppose \(X\) is a random variable which can take values \(x \in \mathcal{X}\).
- \(X\) is a discrete r.v. if \(\mathcal{X}\) is countable.
- \(p(x)\) is the probability of a value \(x\) and is called the probability mass function.
- \(X\) is a continuous r.v. if \(\mathcal{X}\) is uncountable.
- \(f(x)\) is called the probability density function and can be thought of as the probability of a value \(x\).
Probability Mass Function¶
For a discrete random variable the probability mass function (PMF) is
where \(a \in \mathbb{R}\).
Probability Density Function¶
If \(B = (a,b)\)
Strictly speaking
but we may (intuitively) think of \(f(a) = P(X=a)\).
Properties of Distributions¶
For discrete random variables
- \(p(x) \geq 0\), \(\forall x \in \mathcal{X}\).
- \(\sum_{x\in \mathcal{X}} p(x) = 1\).
For continuous random variables
- \(f(x) \geq 0\), \(\forall x \in \mathcal{X}\).
- \(\int_{x\in \mathcal{X}} f(x)dx = 1\).
Cumulative Distribution Function¶
For discrete random variables the cumulative distribution function (CDF) is
- \(F(a) = P(X \leq a) = \sum_{x \leq a} p(x).\)
For continuous random variables the CDF is
- \(F(a) = P(X \leq a) = \int_{-\infty}^a f(x) dx.\)
Expected Value¶
For a discrete r.v. \(X\), the expected value is
For a continuous r.v. \(X\), the expected value is
Expected Value¶
If \(Y = g(X)\), then
- For discrete r.v. \(X\)
- For continuous r.v. \(X\)
Properties of Expectation¶
For random variables \(X\) and \(Y\) and constants \(a,b \in \mathbb{R}\), the expected value has the following properties (for both discrete and continuous r.v.’s):
- \(E[aX + b] = aE[X] + b.\)
- \(E[X + Y] = E[X] + E[Y].\)
Realizations of \(X\), denoted by \(x\), may be larger or smaller than \(E[X]\).
- If you observed many realizations of \(X\), \(E[X]\) is roughly an average of the values you would observe.
Properties of Expectation - Proof¶
Variance¶
Generally speaking, variance is defined as
If \(X\) is discrete:
If \(X\) is continuous:
Variance¶
Using the properties of expectations, we can show \(Var(X) = E[X^2] - E[X]^2\):
Standard Deviation¶
The standard deviation is simply
- \(Std(X)\) is in the same units as \(X\).
- \(Var(X)\) is in units squared.
Covariance¶
For two random variables \(X\) and \(Y\), the covariance is generally defined as
Note that \(Cov(X,X) = Var(X)\).
Covariance¶
Using the properties of expectations, we can show
This can be proven in the exact way that we proved
In fact, note that
Properties of Variance¶
Given random variables \(X\) and \(Y\) and constants \(a,b \in \mathbb{R}\),
The latter property can be generalized to
Properties of Variance - Proof¶
Properties of Covariance¶
Given random variables \(W\), \(X\), \(Y\) and \(Z\) and constants \(a,b \in \mathbb{R}\),
The latter two can be generalized to
Correlation¶
Correlation is defined as
- It is fairly easy to show that \(-1 \leq Corr(X,Y) \leq 1\).
- The properties of correlations of sums of random variables follow from those of covariance and standard deviations above.
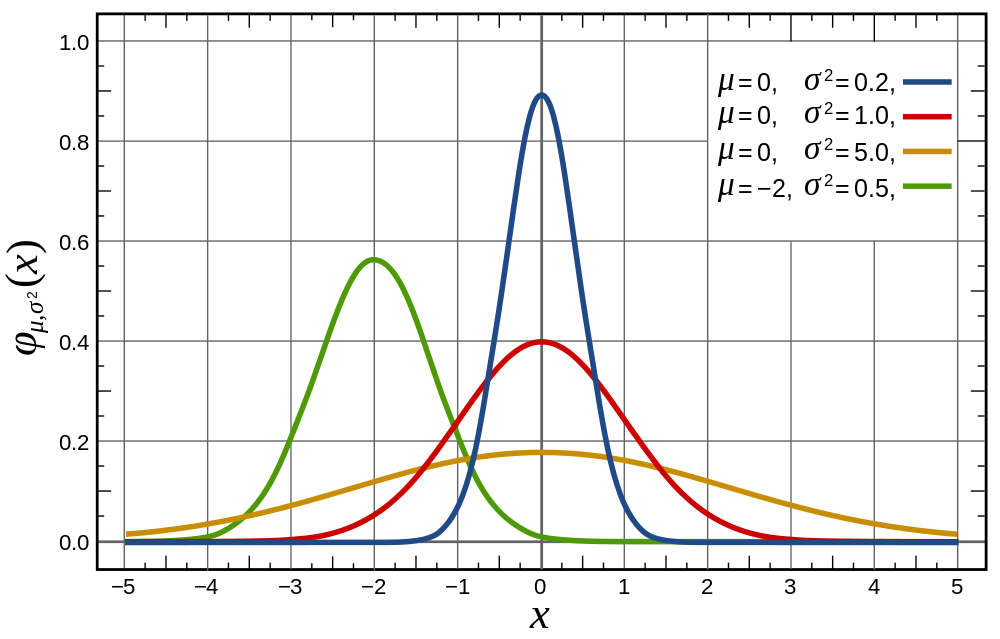
Normal Distribution¶
The normal distribution is often used to approximate the probability distribution of returns.
- It is a continuous distribution.
- It is symmetric.
- It is fully characterized by \(\mu\) (mean) and \(\sigma\) (standard deviation) – i.e. if you only tell me \(\mu\) and \(\sigma\), I can draw every point in the distribution.
Normal Density¶
If \(X\) is normally distributed with mean \(\mu\) and standard deviation \(\sigma\), we write
The probability density function is
Standard Normal Distribution¶
Suppose \(X \sim \mathcal{N}(\mu, \sigma)\).
Then
is a standard normal random variable: \(Z \sim \mathcal{N}(0,1)\).
- That is, \(Z\) has zero mean and unit standard deviation.
We can reverse the process by defining
Standard Normal Distribution - Proof¶
Standard Normal Distribution - Proof¶
Sum of Normals¶
Suppose \(X_i \sim \mathcal{N}(\mu_i, \sigma_i)\) for \(i = 1,\ldots,n\).
Then if we denote \(W = \sum_{i=1}^n X_i\)
How does this simplify if \(Cov(X_i, X_j) = 0\) for \(i \neq j\)?
Sample Mean¶
Suppose we don’t know the true probabilities of a distribution, but would like to estimate the mean.
- Given a sample of observations, \(\{x_i\}_{i=1}^n\), of random variable \(X\), we can estimate the mean by
- This is just a simple arithmetic average, or a probability weighted average with equal probabilities: \(\frac{1}{n}\).
- But the true mean is a weighted average using actual (most likely, unequal) probabilities. How do we reconcile this?
Sample Mean (Cont.)¶
Given that the sample \(\{x_i\}_{i=1}^n\) was drawn from the distribution of \(X\), the observed values are inherently weighted by the true probabilities (for large samples).
- More values in the sample will be drawn from the higher probability regions of the distribution.
- So weighting all of the values equally will naturally give more weight to the higher probability outcomes.
Sample Variance¶
Similarly, the sample variance can be defined as
Notice that we use \(\frac{1}{n-1}\) instead of \(\frac{1}{n}\) for the sample average.
- This is because a simple average using \(\frac{1}{n}\) underestimates the variability of the data because it doesn’t account for extra error involved in estimating \(\hat{\mu}\).
Other Sample Moments¶
Sample standard deviations, covariances and correlations are computed in a similar fashion.
- Use the definitions above, replacing expectations with simple averages.