Prior and Posterior Distributions¶
Prior Distribution¶
Bayes’ Theorem can be used to model the distribution of parameters.
- Recall that the likelihood of data \({\bf y}\) can be expressed as \(f({\bf y}|{\bf \theta})\).
- \({\bf \theta}\) is a vector of parameters.
- In reality, we think of \({\bf \theta}\) as a set of unknown values that are not random.
- However, we treat \({\bf \theta}\) as random because of our lack of knowledge.
- That is, our lack of knowledge induces a distribution over \({\bf \theta}\).
Prior Distribution and Likelihood¶
The prior distribution \(\pi({\bf \theta})\) expresses our beliefs about \({\bf \theta}\) prior to observing data \({\bf y}\).
- \(\pi({\bf \theta})\) is different from the likelihood: \(f({\bf y}|{\bf \theta})\).
- \(\pi({\bf \theta})\) is loosely interpreted as the probability of \({\bf \theta}\) occurring before we observe data.
- \(f({\bf y}|{\bf \theta})\) is loosely interpreted as the probability of the data occurring, given a specific value of the parameter vector \({\bf \theta}\).
Joint Density¶
The joint density of \({\bf y}\) and \({\bf \theta}\) is
- This is analogous to the relationship we previously derived:
Marginal Density¶
The marginal density of \({\bf y}\) is
Marginal Density¶
- This is analogous to the relationship we previously derived:
for a partition \(\{B_i\}_{i=1}^K\).
Posterior Distribution¶
According to Bayes’ Theorem,
- \(\pi({\bf \theta}|{\bf y})\) is referred to as the posterior distribution of \({\bf \theta}\).
- \(\pi({\bf \theta}|{\bf y})\) is loosely interpreted as the probability of \({\bf \theta}\) after observing \({\bf y}\).
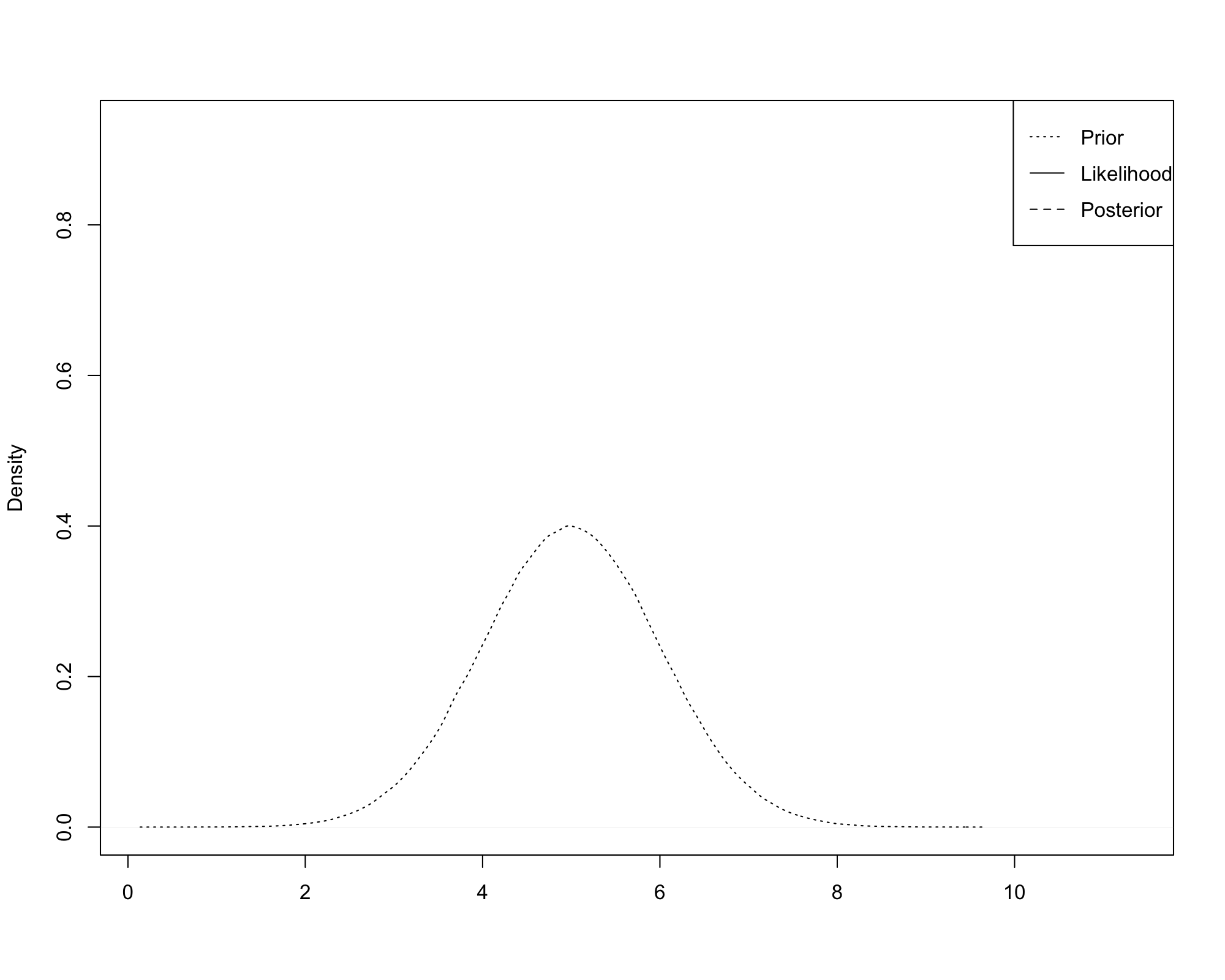
Bayesian Updating¶
Bayesian analysis is a method to use data to update our beliefs about \({\bf \theta}\).
- We begin with a prior distribution \(\pi({\bf \theta})\) which captures our views about the likelihood of \({\bf \theta}\) taking particular values.
- We specify a model for the probability density of the data, given \({\bf \theta}\): \(f({\bf y}|{\bf \theta})\).
- We use the likelihood to update our beliefs about \({\bf \theta}\):
- If the data are very informative, \(\pi({\bf \theta}|{\bf y})\) can be quite different from \(\pi({\bf \theta})\).
A Note on Proportionality¶
Suppose
then
A Note on Proportionality¶
More generally, if
then
A Note on Proportionality¶
Since \(f({\bf y})\) is not a function of \({\bf \theta}\),
- It is often easier to work with only \(f({\bf y}|{\bf \theta})\pi({\bf \theta})\).
Conjugate Priors¶
Our choice of \(\pi({\bf \theta})\) and \(f({\bf y}|{\bf \theta})\) may not yield an analytic solution for \(\pi({\bf \theta}|{\bf y})\).
- \(\pi({\bf \theta}|{\bf y})\) still exists, but it must be computed numerically.
- However, when the likelihood and prior have similar forms, they result in tractable posteriors.
- A conjugate prior is a distribution that results in a posterior of the same family when coupled with a particular likelihood.
Conjugate Priors¶
- For example, if \(f({\bf y}|{\bf \theta})\) is a binomial distribution and \(\pi({\bf \theta})\) is a beta distribution, \(\pi({\bf \theta}|{\bf y})\) will also be a beta distribution.
- Alternatively, if \(f({\bf y}|{\bf \theta})\) is a normal distribution and \(\pi({\bf \theta})\) is a normal distribution, \(\pi({\bf \theta}|{\bf y})\) will also be a normal distribution.
Normal Example¶
Suppose \(Y_1, \ldots, Y_n \stackrel{i.i.d.}{\sim} \mathcal{N}(\mu,\sigma^2)\), where \(\sigma^2\) is known and \(\mu\) is unknown.
- Assume \(\pi(\mu)\) is \(\mathcal{N}(\mu_0, \sigma^2_0)\), where \(\mu_0\) and \(\sigma^2_0\) are known parameters.
- We will see below that \(\sigma^2_0\) provides a measure of how strong our beliefs are that \(\mu = \mu_0\) prior to observing data.
Normal Example¶
The prior is
Normal Example¶
The likelihood is
Normal Example¶
The posterior is
Normal Example¶
Normal Example¶
We see that \(\pi(\mu|Y_1,\ldots,Y_n)\) is \(\mathcal{N}\left(\frac{A}{B}, \frac{1}{B}\right)\) where
Normal Example¶
- If \(\sigma^2_0\) is very small relative to \(\sigma^2/n\), \(E[\mu|Y_1,\ldots,Y_n] \approx \mu_0\) and \(Var(\mu|Y_1,\ldots,Y_n) \approx \sigma^2_0\).
- In this case, the prior is very precise and contains a lot of information - the data doesn’t add much to prior knowledge.
- If \(\sigma^2/n\) is very small relative to \(\sigma^2_0\), \(E[\mu|Y_1,\ldots,Y_n] \approx \bar{Y}\) and \(Var(\mu|Y_1,\ldots,Y_n) \approx \frac{\sigma^2}{n}\).
- In this case, the prior is very imprecise and contains very little information - the data is very informative and adds a lot to prior knowledge.








Bayesian Parameter Estimates¶
The most common Bayesian parameter estimates are
- The mean of the posterior distribution.
- The mode of the posterior distribution.
- The median of the posterior distribution.
- For large \(n\), the the mode is approximately equal to the MLE.
Frequentist Confidence Intervals¶
When constructing typical confidence intervals:
- Parameters are viewed as fixed and data as random.
- The interval is random because the data is random.
- We interpret the interval as containing the true parameter with some probability before the data are observed.
- Once the data are observed, the computed interval either contains or does not contain the true parameter.
- We interpret a 95% confidence interval in the following way: if we could draw 100 samples similar to the one we have, roughly 95 of the associated confidence intervals should contain the true parameter.
Bayesian Credible Intervals¶
Bayesian credible intervals are the Bayesian equivalent to frequentist confidence intervals.
- In the Bayesian paradigm, the parameters are viewed as random while the data are fixed.
- An interval based on the posterior distribution has a natural interpration as a probability of containing the true parameter, even after the data have been observed.
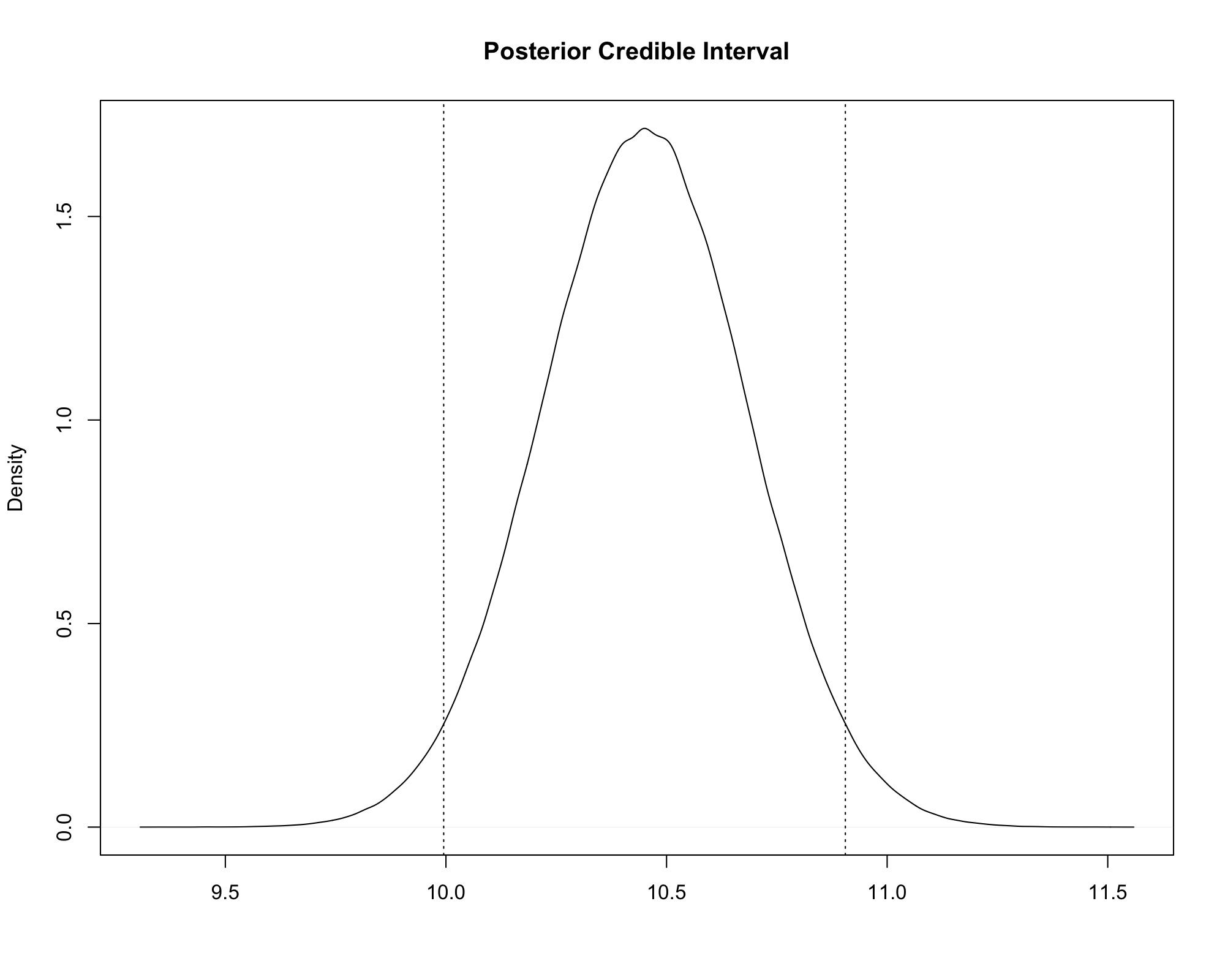
Equal-tails Credible Interval¶
The most basic \(1-\alpha\) credible interval is formed by computing the \(\alpha/2\) and \(1-\alpha/2\) quantiles of the posterior distribution.
- For example, suppose \(\alpha = 0.05\): you want to compute a 95% credible interval.
- Determine the 0.025 and 0.975 quantiles.
- These are the values corresponding to 2.5% of the distribution in the lower tail and 2.5% of the distribution in the upper tail.